lua vm 运行过程中,栈是一个重要的数据结构。
栈是一个很巧妙的设计,它同时能满足 lua、c 函数运行的需要,也能实现 lua 与 c 函数的互相调用。
1. 栈
1.1 栈的数据结构
一个操作系统线程中,可以运行多个 lua vm,lua vm 用 global_State 这个结构体来表示。
一个 lua vm 中,可以运行多条 lua thread,即协程,lua thread 用 lua_State 这个结构体来表示。
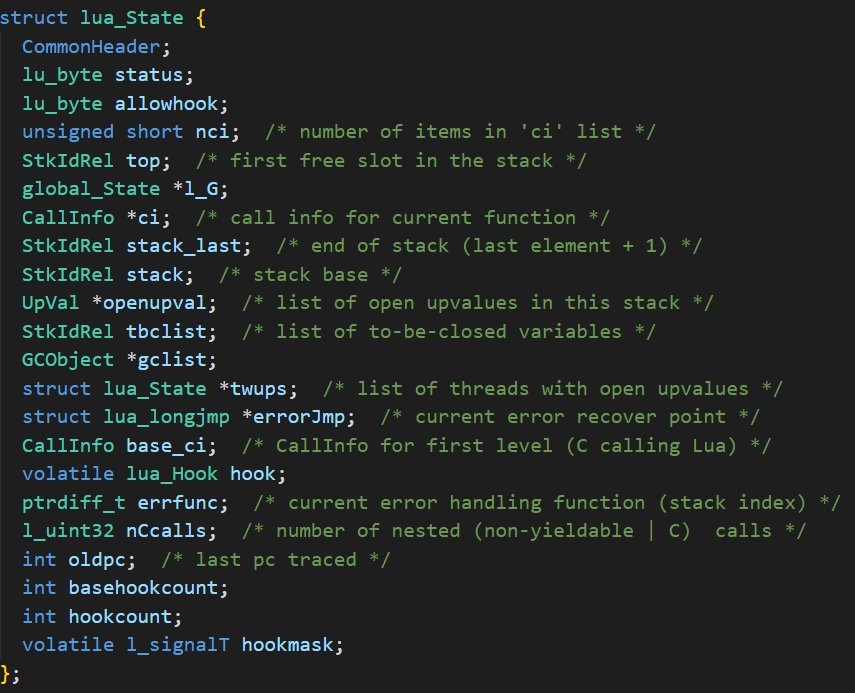
每个 lua thread 都有一个专属的 “栈”,它是一个 StackValue 类型的数组,而 StackValue 内部包含了 TValue,它可以表示 lua vm 中所有类型的变量。
在 lua_State 中,用 stack 和 stack_last 这个字段来描述栈数组,stack 表示数组开头,stack_last 表示数组结尾(真实情况更复杂一点点,末尾还有 EXTRA_STACK 个元素,但问题不大)。
为了与操作系统线程的栈区别开来,这里称 lua 的这个栈为 lua 数据栈。
lua 数据栈的作用是处理函数调用以及存储函数运行时需要的数据。
栈会随着函数调用而增长,增长是通过 luaD_growstack 实现的,但有大小限制,上限为 LUAI_MAXSTACK,在 32位或以上系统中是 1000000,超过就会报 “stack overflow”。
1.2 函数调用与栈的关系
协程执行的过程,就是一个函数调用另一个函数的过程,形成一个函数调用链:f1->f2->f3->....。
函数调用在 lua_State 中用 CallInfo 结构体来表示,由 CallInfo 组成的链表,即是函数调用链。
每个函数在 lua 数据栈上都占用一块空间,其范围是由 CallInfo 的两个字段表述的,func 表示起始位置,top 表示终止位置。一个函数在栈上的数据分布大概是这样的:

func 实际上就是 Closure 类型的数据,TValue 可以表示它,而 arg1 ~ argn 表示函数的 n 个形参,var1 ~ varm 表示函数的 m 个本地变量,形参跟本地变量在 lua 里都称为 local vars。它们是在编译期确定好各自在栈中的位置的,0 到 n+m 这些栈元素,也被称为 “寄存器”,用 R 表示,比如 R[0] 就表示 arg1,而 R[n+1] 表示 var1。
CallInfo 与 stack 的大致对应关系如下:

上图出自 codedump 的《Lua 设计与实现》[1],不过里面有个细节没画准,就是 CallInfo 的 top 指针,不一定是会指在 argn 处的,具体是为什么下面展开讲讲。
1.3 CallInfo 中的 top 字段
图3 中 CallInfo 的 top 字段指向了栈数组中的 argn 项,多数情况下并不是这样的,下面分情况讨论。
1、lua 函数
上图部分情况下准确。在代码中,CallInfo 的 top 指向的是 func + 1 + maxstacksize 这个位置,maxstacksize 是在编译期确定的这个函数需要的 “寄存器” 总数量。一个普通的 lua 函数,需要的寄存器往往不止要用于存放形参,还有一些本地变量,一些运算过程的中间结果,所以 maxstacksize 往往是比形参个数大的。
也就是说,只有当 maxstacksize 刚好是形参的个数时,上图才是准确的。
比如这样一个函数,maxstacksize 就是大于形参个数的:
local function f1(x, y)
local a = x + y
end
编译出来成这样:

locals 那项显示,它至少需要 3 个寄存器,2 个用于存放形参 x 和 y,1 个用于存放本地变量 a。
2、c 函数
上图完全不准确。CallInfo 的 top 指向的应该是 func + 1 + LUA_MINSTACK 这个位置,LUA_MINSTACK 大小为 20,是初始时给 c 函数额外分配的栈空间(除了参数之外的)。
c 函数是通过 lua api 操作 lua 数据栈的,初始的时候,lua_State.top 指向 argn 的位置的。随着 c 函数的运行,比如通过 lua_push 开头的 api 往栈里面压 n 个数据,lua_State.top 就相应的增长 n 个位置。
这也是 lua 数据栈的巧妙之处:
-
当一个 lua 函数调用一个 c 函数,就先把参数放到栈上,而 c 函数被 lua call 的时候,它在运行时可以通过 lua_to 开头的 api 把栈上保存的参数转换成 c 函数自己的变量。
-
当一个 c 函数调用一个 lua 函数时,先通过 lua_push 开头的 api 往栈里压 n 个参数以及 lua 函数,然后再调用 lua_call 完成调用,而调用完成后,lua 函数的返回结果又都保存在栈上,这时候 c 函数又可以通过 lua_to 开头的命令获取这些返回结果。
值得注意的是,写 c 函数的时候,要时刻注意栈空间的大小是否足够。这种情况下 lua 不会惯着你了,初始时只提供了额外的 LUA_MINSTACK 个元素的栈空间。当栈空间不够的时候,要使用 luaL_checkstack 来扩容。
1.4 固定参数的函数调用
固定参数的函数调用比较简单,比如这样一个简单的打印函数:
local function f1(x, y, z)
print(x, y, z)
end
f1(10, 20, 30)
编译出来是这样的:
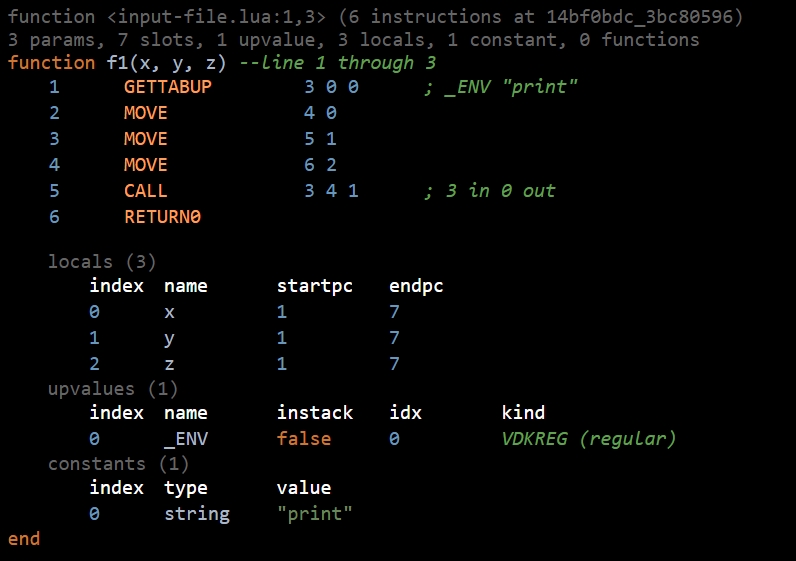
f1 调用 print 的过程中,栈空间布局是这样的:
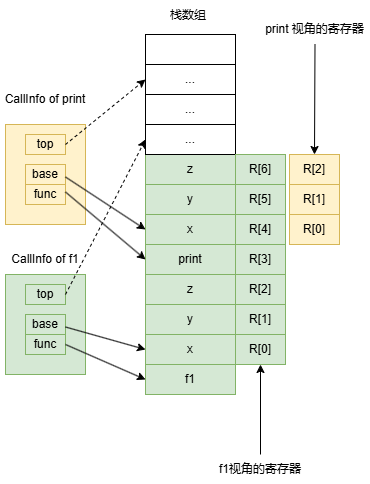
整个调用过程可以归结为三步:
第一、把 print 这个函数入栈。
1 GETTABUP 3 0 0 ; _ENV "print"
通过 GETTABUP 指令,从 _ENV 中把 print 这个函数 (实际上是closure) 复制到 R[3] 寄存器上。
第二、把三个参数入栈。
2 MOVE 4 0
3 MOVE 5 1
4 MOVE 6 2
x,y,z 分别是在 R[0],R[1],R[2],通过 MOVE 指令,把它们复制到 R[4],R[5],R[6] 这几个寄存器上。
第三、调用 print 函数。
5 CALL 3 4 1 ; 3 in 0 out
OP_CALL 的格式是 OP_CALL,/* A B C R[A], ... ,R[A+C-2] := R[A](R[A+1], ... ,R[A+B-1]) */
A 表示函数的位置,即 R[3];
B 表示参数的个数,此处参数个数是确定的,B-1 等于参数个数,这里 B 是 4,刚好对应 3 个参数;
C 表示返回值的个数,1 表示没有返回值;
以上也可以看出,函数占用的栈空间是堆叠在一起的。f1 函数调用 print 函数的时候,要在自己的栈空间上先放入 print 函数的 closure,再放入参数。而当 print 函数开始执行,从 print 函数开始的这段空间又被 print 函数当成自己的栈空间。
1.5 不定参数的函数调用
不定参数调用的时候,比较复杂。当参数个数确定的时候,可以让 OP_CALL 的参数 B 来表示个数,当参数不确定的时候,只能用别的办法。
举个例子:
local function f1()
local t = {10, 20, 30}
print(table.unpack(t))
end
编译出来是这样:

大致步骤如下:
第一、构造表 t,构造完后 t 放在 R[0] 处。
1 NEWTABLE 0 0 3 ; 3
2 EXTRAARG 0
3 LOADI 1 10
4 LOADI 2 20
5 LOADI 3 30
6 SETLIST 0 3 0
第二、从 _ENV 取 print 函数放在 R[1] 处。
7 GETTABUP 1 0 0 ; _ENV "print"
第三、从 _ENV 取 table.unpcak 函数放在 R[2] 处。
8 GETTABUP 2 0 1 ; _ENV "table"
9 GETFIELD 2 2 2 ; "unpack"
第四、从 R[0] 复制表 t 到 R[3] 处。
10 MOVE 3 0
第五、调用 R[2] 处的 table.unpack 函数,所有的结果放在从 R[2] 开始的寄存器处。B = 2 表示只有一个参数 t,C = 0 表示返回所有的结果,并且个数不确定,这时候 lua vm 会把 L->top 设置为 “最后一个结果”,这样后续的函数调用就可以把它当成不确定个数的参数。
11 CALL 2 2 0 ; 1 in all out
第六、调用 R[1] 处的 print 函数,A = 1 表示函数在 R[1] 处;B = 0 表示参数个数不确定,这时候参数就是从 R[A+1] 开始,到 R[A+L->top]为止,即 R[2] 到 R[1+L->top],刚就就是第五步 table.unpack 返回的所有结果。
12 CALL 1 0 1 ; all in 0 out
总结一下,在不定参数的调用中,产生不定参数的函数把结果放到栈上,并设置 L->top 指向最后一个结果,而调用方在 OP_CALL 时把 B 设为 0,表示使用栈上 R[A+1] 到 R[A+L->top] 这一段栈空间上的所有元素作为参数。
1.6 OP_CALL 的完整规则[2]
Syntax
CALL A B C R(A), ... ,R(A+C-2) := R(A)(R(A+1), ... ,R(A+B-1))
Description
Performs a function call, with register R(A) holding the reference to the function object to be called. Parameters to the function are placed in the registers following R(A). If B is 1, the function has no parameters. If B is 2 or more, there are (B-1) parameters. If B >= 2, then upon entry to the called function, R(A+1) will become the base.
If B is 0, then B = ‘top’, i.e., the function parameters range from R(A+1) to the top of the stack. This form is used when the number of parameters to pass is set by the previous VM instruction, which has to be one of OP_CALL or OP_VARARG.
If C is 1, no return results are saved. If C is 2 or more, (C-1) return values are saved. If C == 0, then ‘top’ is set to last_result+1, so that the next open instruction (OP_CALL, OP_RETURN, OP_SETLIST) can use ‘top’.
2. 参考
[1] codedump. Lua 设计与实现. 北京: 人民邮电出版社, 2017.8: 45.
[2] dibyendumajumdar. op-call-instruction. Available at https://the-ravi-programming-language.readthedocs.io/en/latest/lua_bytecode_reference.html#op-call-instruction.